We propose Lavida-O, a unified Masked Diffusion Model (MDM) for multimodal understanding and generation. Unlike existing multimodal MDMs such as MMaDa and Muddit which only support simple image-level understanding tasks and low-resolution image generation, Lavida-O presents a single framework that enables image-level understanding, object grounding, image editing, and high-resolution (1024px) text-to-image synthesis. Lavida-O incorporates a novel Elastic Mixture-of-Transformers (Elastic-MoT) architecture that couples a lightweight generation branch with a larger understanding branch, supported by token compression, universal text conditioning and stratified sampling for efficient and high-quality generation. Lavida-O further incorporates planning and iterative self-reflection in image generation and editing tasks, seamlessly boosting generation quality with its understanding capabilities. Lavida-O achieves state-of-the-art performance on a wide range of benchmarks including RefCOCO object grounding, GenEval text-to-image generation, and ImgEdit image editing, outperforming existing autoregressive models and continuous diffusion models such as Qwen2.5-VL and FluxKontext-dev, while offering considerable speedup at inference. These advances establish Lavida-O as a new paradigm for scalable multimodal reasoning and generation.
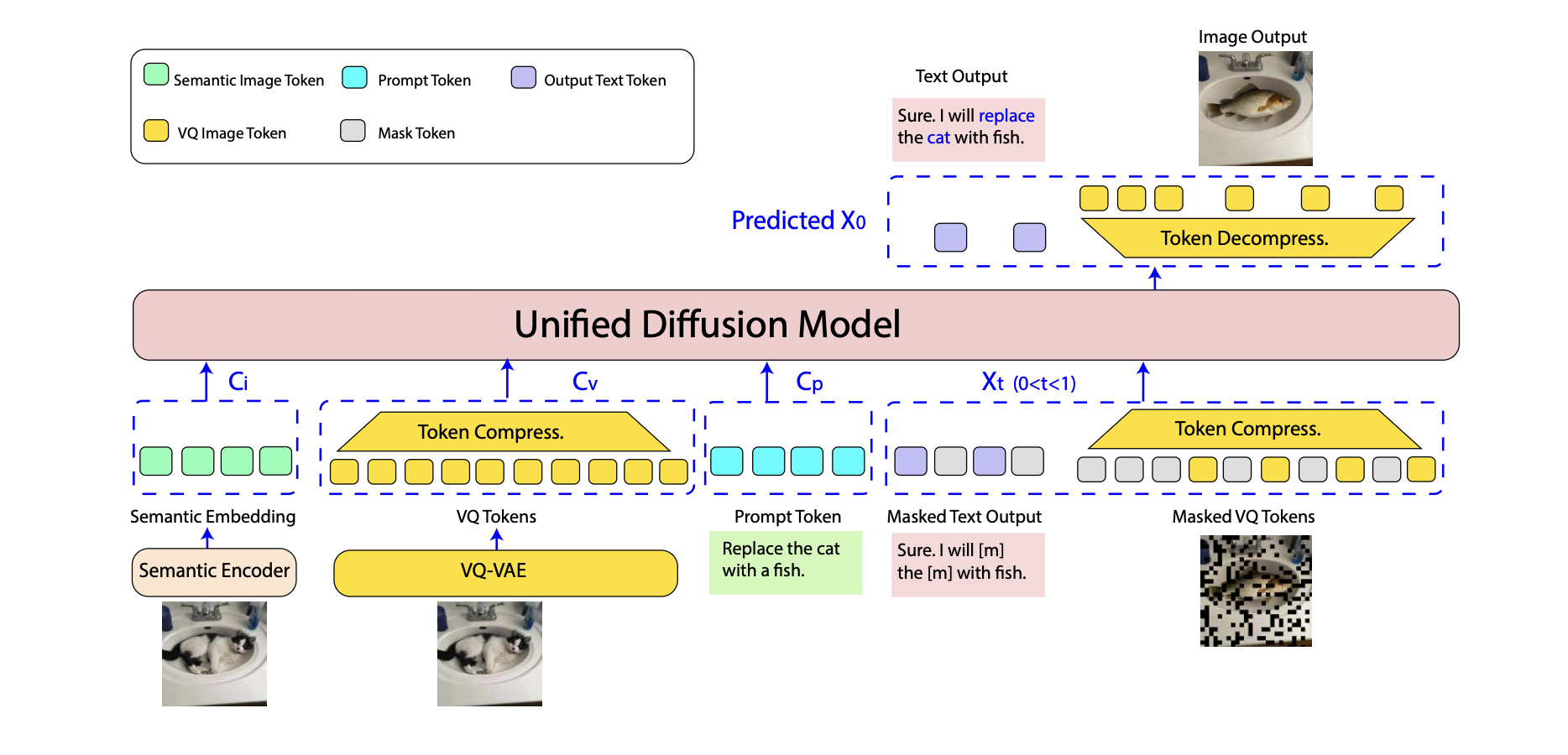
LaViDa-O employs a Senmantic-Encoder and VQ-Enocder to enocde input images. The output images are represented by discrete VQ tokenize, allowing seamless integration with text tokens for unified understanding and generation.
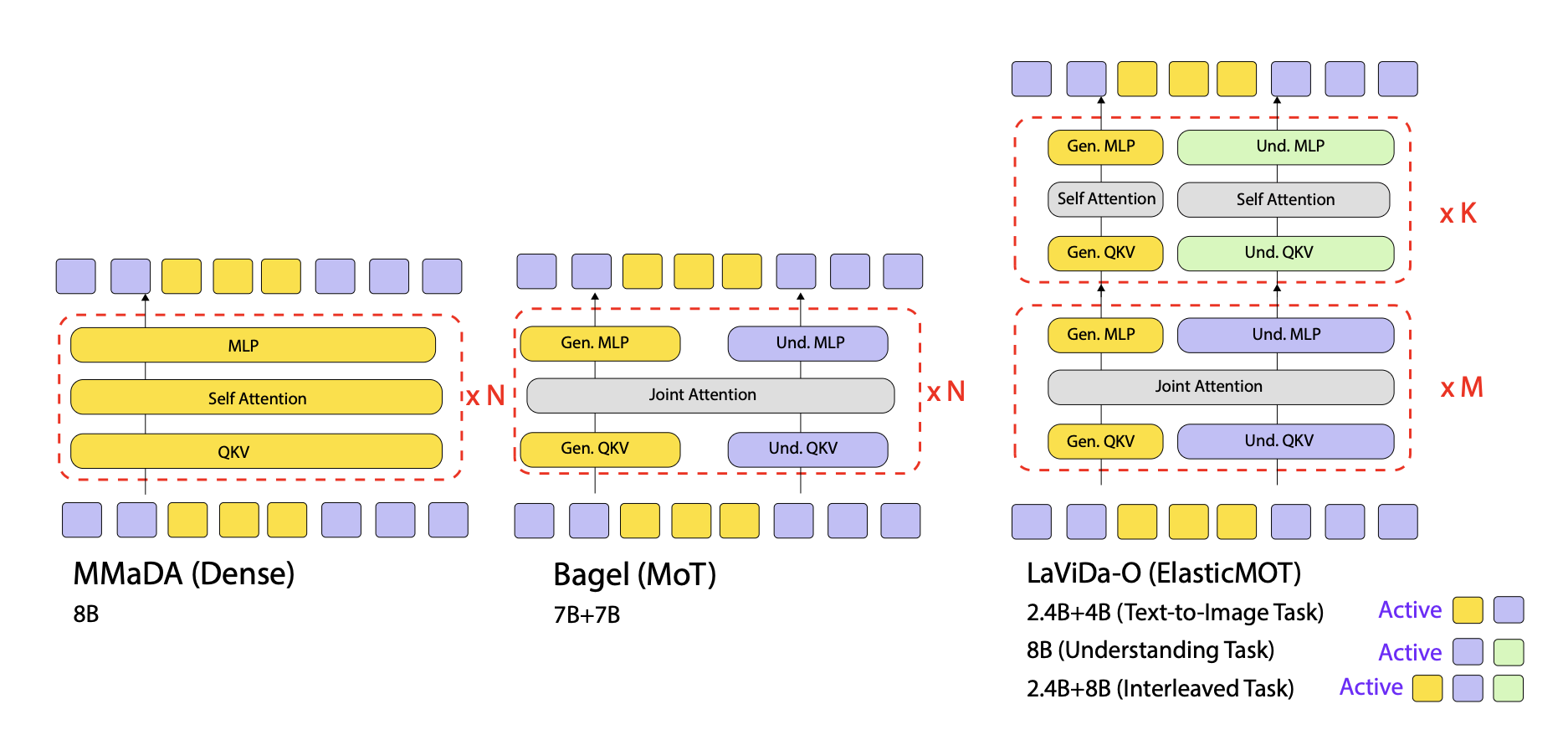
LaViDa-O employs a flexible Elastic-MoT design, with a lightweight generation branch and a larger understanding branch. The two branches can be flexibly activated depending on the tasks to optimize training and inference efficiency.

LaViDa-O introduces a novel paradigm that explicitly leverages the understanding capabilities of a unified model to improve its generation through planning and self-reflection. This design greatly improves the instruction following capabilities in text-to-image generation and image editing tasks.
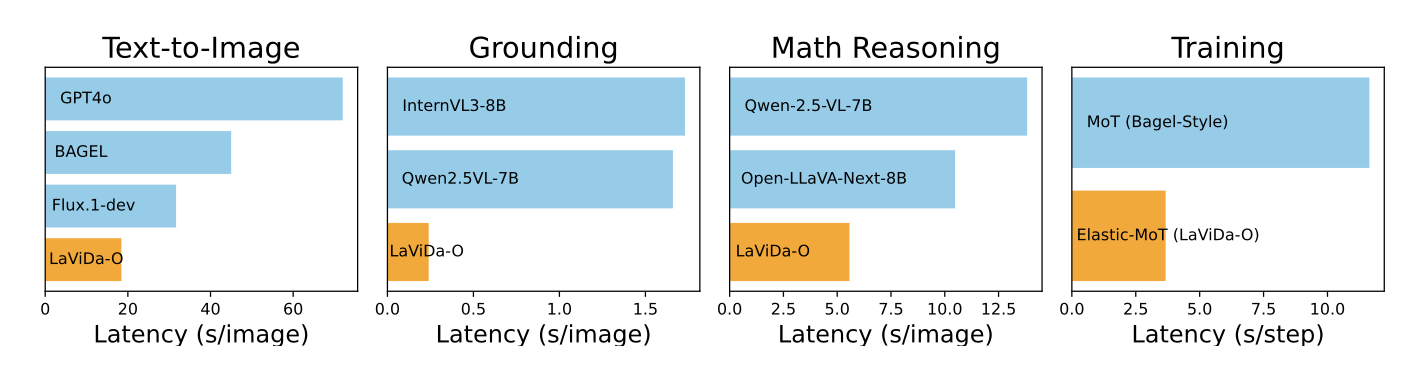
Thanks to the parallel decoding process of diffusion models and the efficient Elastic-MoT architecture, LaViDa-O achieves significantly faster inference speed than existing autoregressive models (e.g., Qwen2.5-VL) and continuous diffusion models (e.g., FluxKontext-dev) on various tasks. Most notably, it achiecevs a 6.8x speedup over Qwen2.5-VL on object grounding.